Big Data
Big Data es una definición utilizada en tecnología para referirse a la información o grupo de datos que por su elevado volumen, diversidad y complejidad no pueden ser almacenados ni visualizados con herramientas tradicionales. Las dimensiones de estos datos obligan a las empresas a buscar soluciones tecnológicas para gestionarlos, pues un buen manejo del Big Data puede representar nuevas métodos para la toma de decisiones y oportunidades de negocio. El reto consiste en saber distinguir lo válido de lo superfluo y sacar provecho de ello.
Introducción a Big Data
Con los avances de los dispositivos móviles, las redes sociales y el Internet de las cosas (IoT) enormes cantidades de datos complejos, tanto estructurados como no estructurados son capturados con la esperanza de permitir a las organizaciones mejorar las decisiones comerciales ya que los datos ahora son vitales para una organizaciones éxito.
Un estudio realizado por IDC indica solo el 0,5% de los datos generados a nivel mundial se analizan. En un mundo donde cada dos días creamos tanta información como lo hicimos desde el comienzo del tiempo hasta 2003 hay una necesidad de tender un puente datos analizados con las tendencias actuales para mejores modelos comerciales. El procesamiento y análisis sistemático de Bigh Data es el factor diferencial.
El fenómeno del análisis de Big Data es continuo creciendo a medida que las organizaciones remodelan sus procesos operativos confiando en los datos en vivo con la esperanza de impulsar técnicas de marketing efectivo, mejorar el compromiso del cliente y potencialmente proporcionar nuevos productos y servicios.
¿Qué es Big Data?
Big Data se refiere a grandes conjuntos de datos complejos, tanto estructurados y no estructurados que el procesamiento y técnicas y algoritmos tradicionales no pueden procesar. Esto permite revelar patrones ocultos y ha llevado a una evolución de una ciencia basada en modelos a una ciencia basada en datos.

Big data se basa en el procesamiento, análisis y visualización de grandes bases de datos, no necesariamente estructuradas, para la toma de decisiones. Este enfoque, relativamente reciente, está adquiriendo una gran relevancia gracias a la acumulación masiva de datos favorecida por la implantación generalizada de las tecnologías de la información y la comunicación. Concretamente, 2002 fue el año en que el volumen de información digitalizada superó por primera vez la cantidad de información almacenada de forma analógica y puede ser considerado, por tanto, como el inicio de la era digital de la información. Actualmente, sobre todo desde la generalización del uso de las redes sociales y los smartphones, esta cantidad de información digitalizada crece de forma exponencial. Algunos sectores, como el comercial y financiero, han sido los principales impulsores de esta tecnología, teniendo a las grandes empresas tecnológicas como las principales pioneras. Éstas integran de forma estratégica en su negocio los avances y descubrimientos que van realizando, a los que, de forma pública, se tiene difícil acceso. Por otro lado, los datos relacionados con la salud también han estado siguiendo esta tendencia. Así, gracias a Internet, la popularización de los smartphones y la aparición de multitud de sensores y redes sociales, los datos masivos, que incluyen no sólo registros clínicos y operacionales sino también texto, audio o vídeo y multitud de registros biométricos, son susceptibles de ser analizados para proporcionar información nueva y útil para los sistemas de salud.
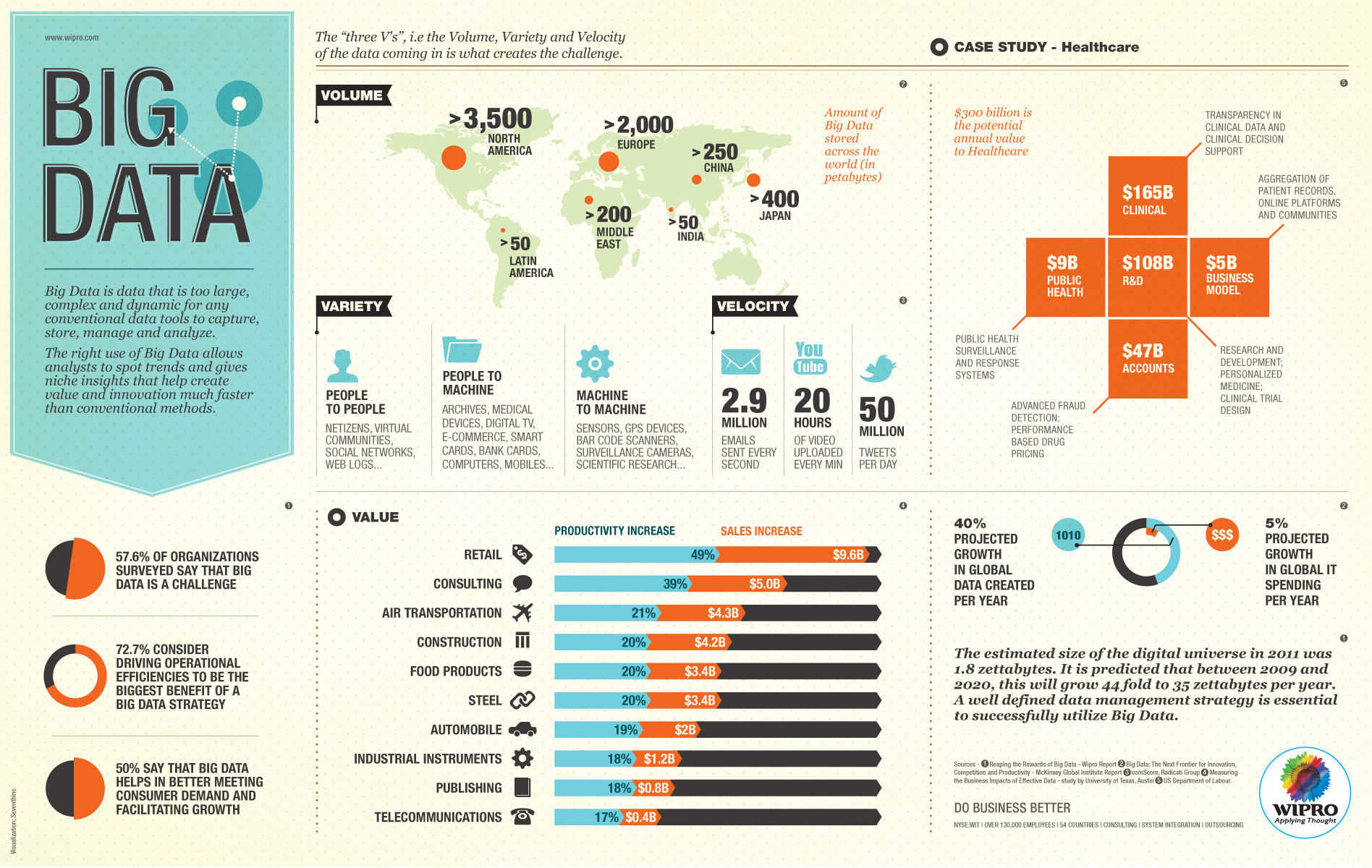
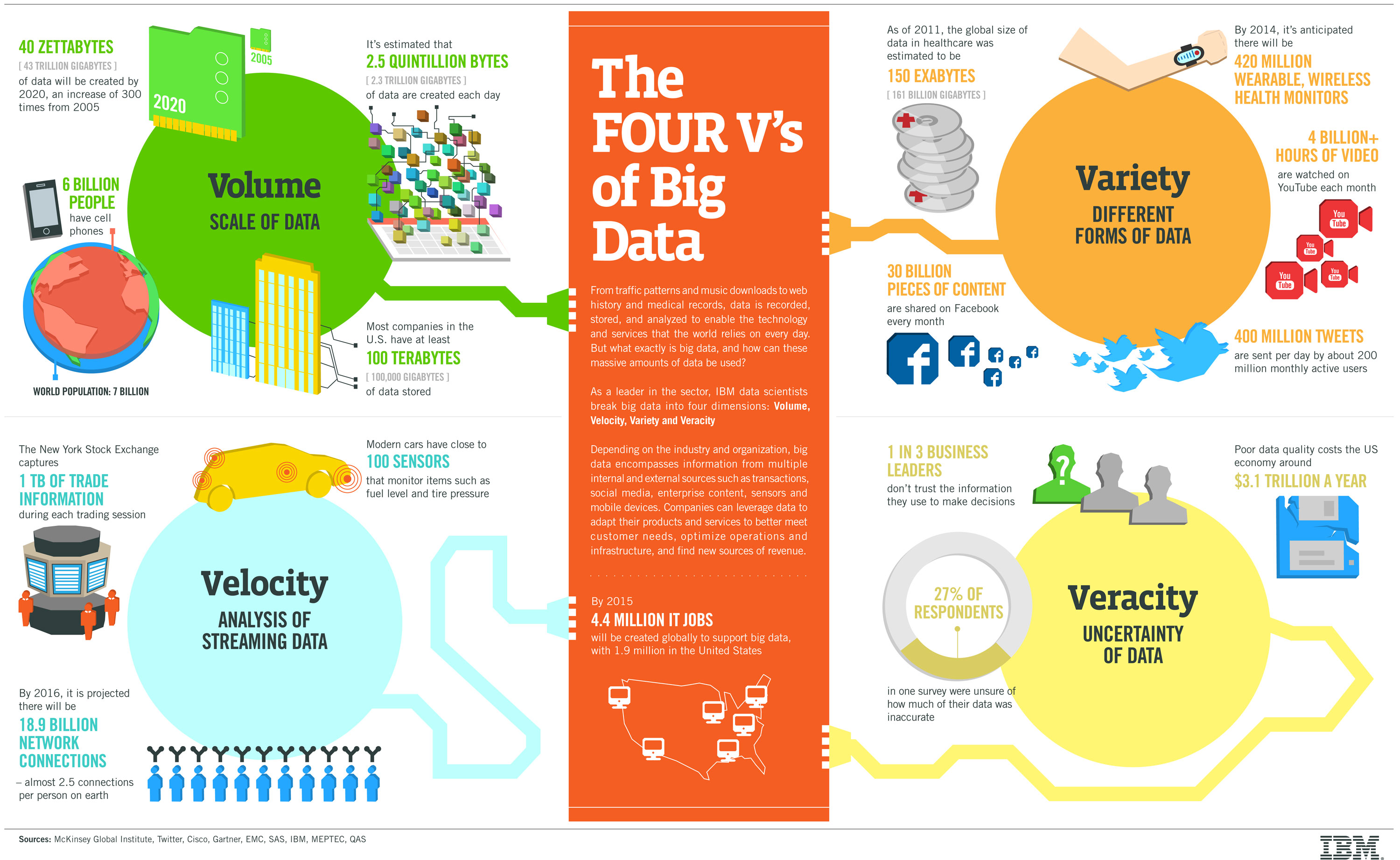
Las Vs de Big Data
Los científicos de IBM mencionan que Big Data tiene cuatro dimensiones: Volumen, velocidad, variedad y veracidad.
Volumen
Los datos actuales existentes están en petabytes, lo que ya es problemático; se predice que en los próximos años aumentarán a zettabytes. Esto se debe al aumento del uso de dispositivos móviles dispositivos y redes sociales principalmente.

La característica principal que define Big Data es la gran cantidad de volumen de información que maneja. Esta masiva cantidad de datos se acumula con un crecimiento exponencial, ampliando continuamente las estructura de almacenamiento de datos existentes. En este sentido, es importante remarcar que los costes asociados a la recogida, almacenamiento y proceso de datos derivados de la proliferación de dispositivos conectados entre sí y a Internet se reducen continuamente. En la actualidad, cuando se habla de bases de datos masivas se refiere a magnitudes del orden de petabytes (1015 bytes) o exabytes (1018 bytes).
Velocidad
Otra de las características esenciales de Big Data es la enorme velocidad en la generación, recogida y proceso de la información. Así, la tecnología Big Data ha de ser capaz de almacenar y trabajar en tiempo real con las fuentes generadoras de información como sensores, cámaras de videos, redes sociales, blogs, páginas webs y otras fuentes que generan millones de datos al segundo. Por otro lado, la capacidad de análisis de dichos datos ha de ser muy veloz reduciendo los tiempos de procesamiento que presentaban las herramientas tradicionales de análisis.
Se refiere tanto a la velocidad a la cual los datos son capturado y la tasa de flujo de datos. El incremento de la velocidad de los datos en vivo causa desafíos para análisis tradicionales ya que los datos son demasiado grandes y están continuamente en movimiento.
Variedad
Como los datos recopilados no son específicos de una categoría o de una sola fuente, hay numerosos formatos de datos en bruto, obtenidos de la web, textos, sensores, correos electrónicos, etc. que son estructurados o no estructurados. Esta gran cantidad hace que los viejos métodos analíticos tradicionales fallen manejando Big Data.
Finalmente, la tercera de las “v” que explica Big Data es la elevada capacidad de agregar información procedente de una amplia variedad de fuentes de información independientes , como redes sociales, sensores, máquinas o personas individuales. Son tantas que se precisan las nuevas tecnologías para analizar este tipo de datos con el fin de obtener una ventaja competitiva. En este sentido, los sistemas Big Data permiten la integración de datos de origen cuantitativo naturalmente desestructurados, así como gráficos, texto, sonido o imágenes.
Los datos no estructurados representan un poderoso recurso sin explotar que tiene el potencial de proporcionar una visión más profunda de los clientes y las operaciones y, en última instancia, ayudar a impulsar la ventaja competitiva. Sin embargo, estos datos no pueden gestionarse fácilmente con las bases de datos relacionales y las herramientas de inteligencia de negocio tradicionales.
Veracidad
La ambigüedad dentro de los datos es el principal foco en esta variable, típicamente el ruido y anormalidades dentro de los datos.
Big Data ha de ser capaz de tratar y analizar inteligentemente el gran volumen de datos con la finalidad de obtener una información verídica y útil que nos permita mejorar nuestra toma de decisiones.
Equipar a una empresa con el comercio electrónico impulsado por Big Data la arquitectura ayuda a obtener una amplia "percepción del cliente" comportamiento, tendencias de la industria, decisiones más precisas para mejorar casi todos los aspectos del negocio, desde marketing y publicidad, a merchandising, operaciones y incluso retención de clientes ".
Con aproximadamente 2.5 quintillones de bytes de datos siendo creado todos los días, es comprensible por qué las empresas La inteligencia (BI) está derivando hacia procesos analíticos que implica la extracción de conjuntos de datos más grandes, como los sistemas de gestión no pueden comprender estas cantidades de datos. Los datos se recopilan constantemente a través de dispositivos diseñados para ayudar a explorar varios sistemas complejos. Estas secuencias de datos cuando se analizan correctamente utilizando grandes los métodos de datos ayudarán a predecir la posibilidad de aumentar la productividad, la calidad y la flexibilidad. El poder de los grandes datos es su capacidad de producir medidas mucho más inteligentes de formular decisiones.
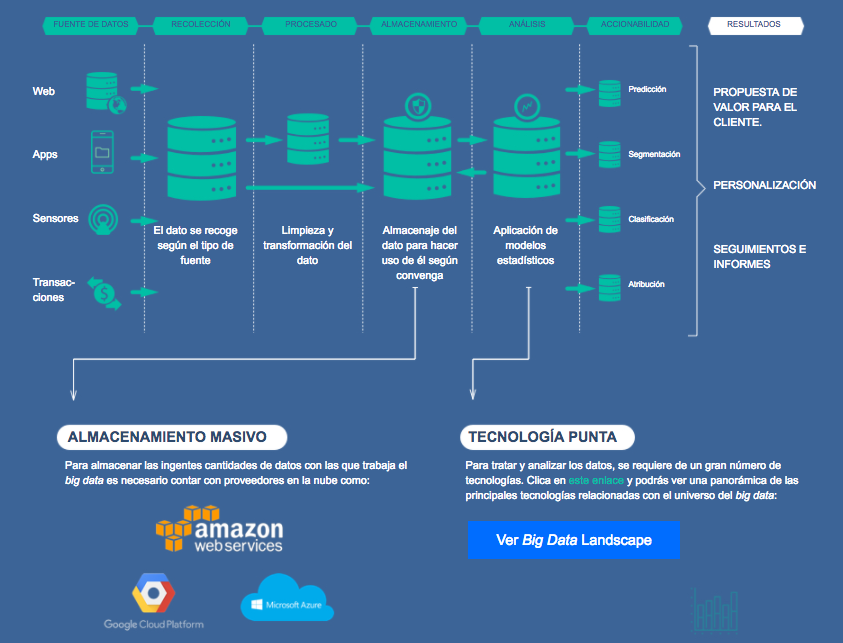
Fuentes de información en Big Data
Se ha comentado que Big Data va más allá del volumen de información para abarcar características tales como la variedad de los datos; la velocidad de almacenamiento y proceso, y de forma muy significativa, en lo que respecta específicamente a la atención médica, a su veracidad. Para ello, es imprescindible la calidad de la información que se obtiene.
En este sentido, se antoja imprescindible acercarse a las diferentes fuentes de información para el Big Data en salud. Podría afirmarse que la información generada proviene de alguna de las siguientes tipologías de fuentes de información:
Web y redes sociales
La generación e interacción de datos de social media como Facebook, Twitter, o Linkedin, además de la información de sitios web de salud o las aplicaciones de smartphones.
Máquina a máquina (M2M)
La información proveniente de las lecturas de los sensores, medidores y otros dispositivos.
Transacciones de datos
Reclamaciones de atención médica y otros registros de facturación cada vez más disponibles en formatos semiestructurados y no estructurados.
Datos biométricos
Huellas dactilares, genéticos, escáner de retina, rayos X y otras imágenes médicas, la presión arterial, el pulso y lecturas de oximetría de pulso y otros tipos similares de datos.
Generados por humanos
Datos no estructurados y semiestructurados, tales como registros electrónicos, notas de los profesionales, correos electrónicos y documentos en papel.

Big Data y Business Intelligence
Aunque se trata de un concepto relativamente nuevo, Big Data no ha surgido de la nada, ya que se puede entender como una evolución del concepto Business Intelligence (BI), que utilizan sobre todo los gestores para convertir sus empresas en organizaciones eficaces y eficientes
Así, el BI tradicional captura información de las fuentes disponibles en la organización y tras la aplicación de algoritmia de análisis muestra unos resultados que tienen la finalidad de ayudar a la toma de decisiones estratégicas en la empresa. Aun así, es importante remarcar que toda la información analizada y visualizada desde BI proviene de fuentes de datos estructuradas. De esta manera, la gran novedad que aporta Big Data es la capacidad de procesar información no estructurada, como por ejemplo: lenguaje natural; información proveniente de las redes sociales; información proveniente de los diferentes dispositivos llevables (wearables), de los diferentes componentes de telemedicina o de variados sensores que pueden proporcionar datos +muy valiosos al sector.
En este sentido, la principal diferencia radica en la estructura de datos. Así, los métodos tradicionales de Business Intelligence se basan en agrupar los datos empresariales en un servidor central y analizarlos de forma offline. De esta manera, los datos se estructuran en una base de datos relacional convencional con un conjunto adicional de índices y formas de acceso a las tablas.
En cambio, en Big Data los datos se almacenan en un sistema de ficheros distribuido en un entorno más flexible y permiten manejar cantidades más grandes de información de forma más ágil.
Finalmente, la tecnología Big Data emplea procesamiento paralelo masivo de datos, mejorandola velocidad del análisis. Este proceso masivo de datos se ejecuta de forma simultánea y en paralelo, unificando los resultados parciales en resultados globales
Big Data y Data Warehouse
Un Data Warehouse es un almacén de datos, no volátil, integrado, creado con el fin de permitir la toma de decisiones en la organización. Es decir, es una arquitectura de datos. En cambio, una solución Big Data es al mismo tiempo una arquitectura de datos y una tecnología de proceso, análisis y visualización de datos.
Big data y minería de datos
Big Data y minería de datos también se refieren a dos realidades diferentes. Mientras ambos conceptos se relacionan con el uso de grandes conjuntos de datos para su proceso y análisis, los dos términos divergen en su operativa.
La minería de datos se refiere al manejo de grandes conjuntos de datos para buscar información pertinente u oportuna. En este sentido, en minería de datos los decisores necesitan tener acceso a partes pequeñas y específicas de los datos dentro de esos grandes conjuntos. Así, se utiliza la minería de datos para descubrir piezas de información concreta. La minería de datos implica el uso de diferentes tipos de paquetes de software para el análisis estadístico. En general, se refiere a las operaciones que implican sofisticadas operaciones de búsqueda de información que devuelven resultados específicos y concretos.

Big Data y computación en la Nube
Big Data es, en el sector de tecnologías de la información y la comunicación, una referencia a los sistemas que se centran en la captura, el almacenamiento, la búsqueda, la compartición, el análisis y la visualización de los datos.
La computación en la nube, del inglés cloud computing, es un paradigma que permite ofrecer servicios de computación a través de Internet.
Grandes empresas de Cloud Computing
Big Data y Machine Learning
Machine Learning es una disciplina científica que trata de que los sistemas informáticos aprendan automáticamente. Es decir, que los sistemas y los algoritmos que revisan los datos, sean capaces de identificar patrones complejos entre volúmenes enormes de información.
En Big Data, las herramientas de análisis tradicionales no son las más adecuadas para capturar el valor total que se puede obtener. El volumen de datos es demasiado grande para un análisis integral tradicional; es demasiado grande para que un analista pueda probar todas las hipótesis y obtenga todo el potencial valor subyacente en los datos. En este contexto, el aprendizaje automático es ideal para aprovechar las oportunidades ocultas en Big Data.
Machine Learning (junto a Big Data) obtiene más valor de las fuentes de datos, sobre todo si son de estructura heterogénea y de elevado volumen. Además, a diferencia de los análisis tradicionales, Machine Learning se nutre de conjuntos de datos en constantemente crecimiento. Cuantos más datos se introducen en un sistema de aprendizaje automático, más puede aprender el algoritmo y obtener resultados de mayor calidad.
Big Data y Open Data
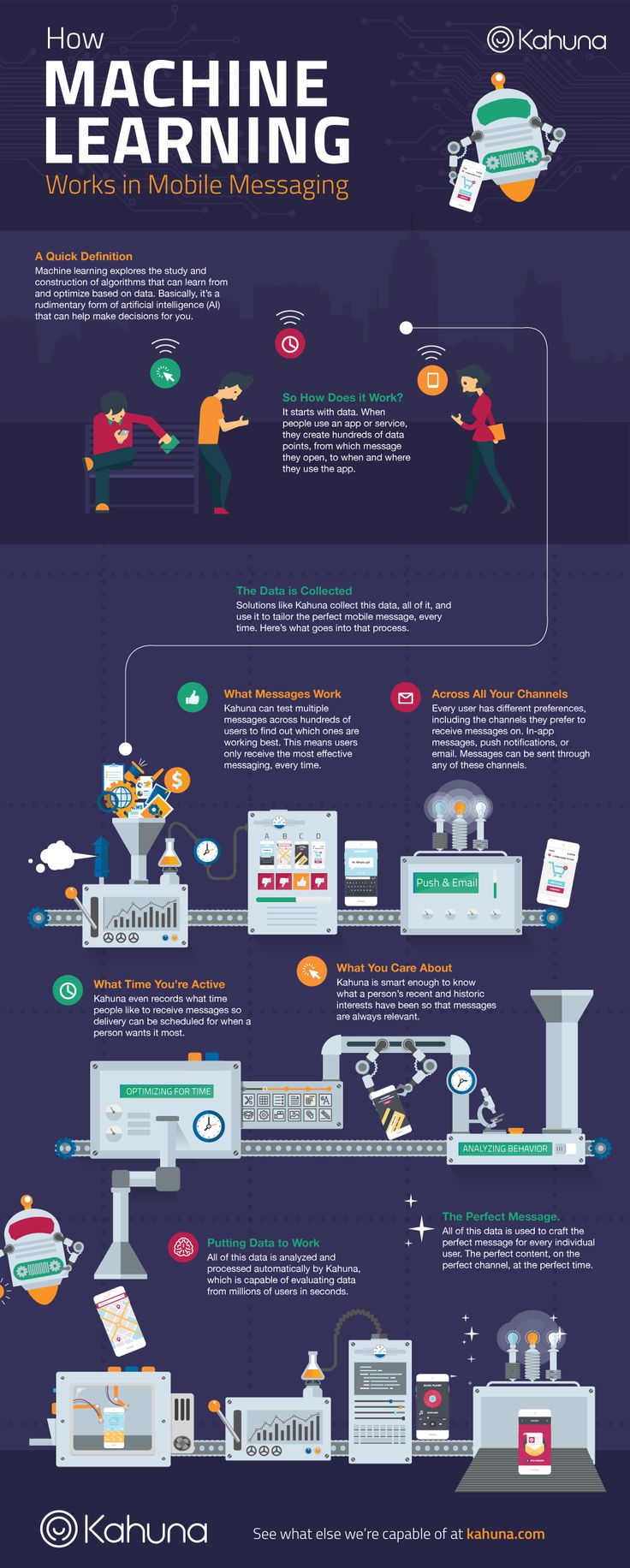
Según OpenDataHandbook una iniciativa de Open knowledge Foundation con el objetivo de servir de guía universal para el desarrollo y promoción del Open Data: “los datos abiertos son datos que pueden ser utilizados, reutilizados y redistribuidos libremente por cualquier persona, y que se encuentran sujetos, cuando más, al requerimiento de atribución y de compartirse de la misma manera en que aparecen”. En este sentido, la diferencia entre Big Data y Open Data estriba en que el primero es un paradigma completo de recogida, almacenamiento y procesamiento de la información y el segundo se refiere esencialmente al carácter abierto de los datos.
Infraestructura y Big Data
Big data requiere un enfoque propio, que debe superar las prácticas habituales redundando en una mayor descentralización y flexibilidad de la arquitectura de datos para poder gestionar las plataformas de Big Data a gran escala y adaptarse a las nuevas demandas de infraestructura de red. Estos nuevos modelos de computación distribuida gestionan datos no estructurados y permiten desarrollar tareas muy intensivas de computación masiva mediante el análisis de grandes cantidades de datos en entornos distribuidos.
La relativa inmadurez del mercado y la naturaleza ‘open source’ de muchas de sus soluciones provoca una gran fragmentación de soluciones tecnológicas en Big data que suelen resolver sólo algunos aspectos concretos y específicos.
Así, el abanico de soluciones tecnológicas entre las que elegir en el momento de implementar un proyecto de Big Data es amplísimo y no deja de crecer, lo cual puede suponer una barrera de entrada para muchas empresas y organismos públicos que carecen de profesionales especialistas en estas nuevas tecnologías. Ante esta situación, un buen asesoramiento será fundamental a la hora de definir un proyecto de Big Data y será necesario identificar las fuentes de datos de mayor valor (tanto internas como externas) y seleccionar las herramientas más adecuadas.
Sistemas de gestión de bases de datos
El concepto sistema de gestión de base de datos es un término genérico que engloba una enorme variedad de herramientas que, en su mayoría, trabajan de forma diferente. Estas aplicaciones gestionan la agregación de la información contenida en las organizaciones. Como los datos pueden estructurarse en diferentes formas y tamaños, se han desarrollado múltiples sistemas de gestión de esta información, al mismo tiempo que se han desarrollado una gran variedad de aplicaciones para solventar las diferentes necesidades de programación.
Así, los sistemas de gestión de bases de datos se basan en los diferentes modelos de bases de datos y en sus estructuras definidas. En este sentido, en las últimas décadas, la opción predominante han sido los sistemas de gestión de bases de datos relacionales.
Modelo relacional y modelo NoSql
Los sistemas de bases de datos basados en el modelo relacional han acabado resultando una solución muy eficiente y fiable y están enormemente extendidos. Los sistemas relacionales requieren esquemas claramente definidos para poder trabajar con los datos. Estos formatos determinan cómo se organizan y utilizan los datos y se parecen a las tablas de doble entrada en filas y columnas, desde los cuales evolucionan.
A pesar de ello, el modelo relacional tiene diferentes contingencias que limitan las capacidades que puede ofrecer. Así, recientemente, toda una serie de diferentes sistemas y aplicaciones llamadas bases de datos NoSLQ han empezado a ganar popularidad. Éstos eliminan muchas de las restricciones propias del modelo relacional y ofrecen nuevas maneras de gestionar los datos de manera eficiente, permitiendo un uso más libre y flexible.
Hadoop
Apache Hadoop es una de las herramientas más conocidas en Big Data. Es un framework de código libre para el almacenamiento y proceso de datos distribuido para grandes volúmenes de datos que puede funcionar en cualquier sistema genérico de hardware
Hadoop incluye una gran variedad de herramientas con utilidades concretas, algunas de las cuales son: tecnologías para el escalado eficiente del almacenamiento de datos (HDFS); herramientas para la gobernanza e integración de datos (Atlas, Falcon, Flume o Scoop); herramientas para la seguridad de datos; o herramientas sobre gestión operativa del sistema.
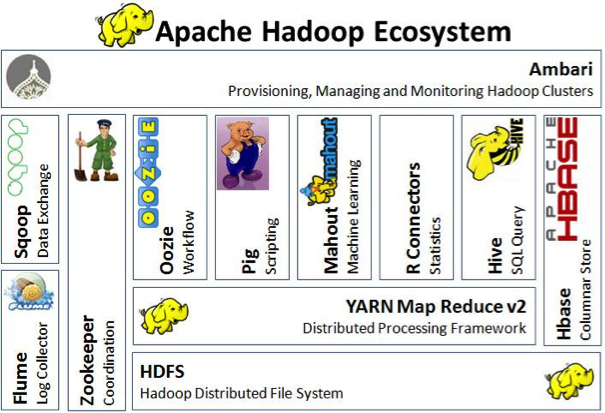
De todas ellas, una de las más conocidas es MapReduce, paradigma de programación que permite la escalabilidad masiva a través de una gran cantidad de servidores en un clúster Hadoop con datos de escalado horizontal.
Tipos de análisis en Big Data
A continuación se presentan de forma resumida los tres principales tipos de análisis en Big Data:
Modelos predictivos
Analizan los resultados anteriores para evaluar qué probabilidad tiene un individuo de mostrar un comportamiento específico en el futuro con el fin de mejorar la eficacia. Esta categoría también incluye modelos que buscan patrones discriminadores de datos para responder a las preguntas sobre el comportamiento, tales como la detección de fraudes. Los modelos de predicción a menudo realizan cálculos en tiempo real, durante las operaciones, por ejemplo, para evaluar un determinado riesgo u oportunidad, a fin de orientar una decisión adecuada.
Modelos descriptivos
Describen las relaciones entre los datos para poder clasificar a los individuos en grupos. A diferencia de los modelos de predicción que se centran en predecir el comportamiento de un único individuo, los modelos descriptivos identifican diferentes relaciones entre individuos. Pero los modelos descriptivos no clasifican a los clientes según su probabilidad de tomar una acción en particular. Las herramientas de modelado descriptivo pueden ser utilizadas para desarrollar modelos simulando una gran cantidad de agentes individuales pudiendo predecir también acciones futuras.
Modelos de decisión
Describen la relación entre todos los elementos de una decisión, incluidos los resultados de los modelos de predicción, la decisión a tomar y el plan de variables y valores que determinan la propia decisión, con la finalidad de predecir los resultados mediante el análisis de muchas variables. Estos modelos pueden ser también utilizados para diferentes procesos de optimización.
Normativa sobre Big Data
Los miembros de la Unión Internacional de Telecomunicaciones (UIT) aprobaron, el 6 de noviembre de 2015, la primera norma de la organización sobre los grandes volúmenes de datos o Big Data.
En esta norma internacional se detallan los requisitos, las capacidades y casos de utilización de Big Data en la nube. La Recomendación UIT-T Y.3600 "Grandes volúmenes de datos – requisitos y capacidades basados en la computación en la nube" (UIT, 2015), fue elaborada por el grupo de expertos del UIT-T encargado de los aspectos relacionados con la computación en la nube y redes móviles.
En ella se describen el significado de Big Data y las características del ecosistema de Big Data desde la perspectiva de la normalización. La norma detalla cómo aprovechar los sistemas de computación en la nube para ofrecer servicios de Big Data y cómo ayudar a la industria para la gestión de grandes conjuntos de datos imposibles de transferir y analizar utilizando tecnologías tradicionales de gestión de datos.
Por otro lado, en el mismo documento, la UIT señala los principales desafíos a los que Big Data debe dar respuesta:
La heterogeneidad de los datos y los datos incompletos: los datos procesados a partir de Big Data pueden pasar por alto algunos atributos o introducir “ruido estadístico” en la transmisión de los mismos datos. Incluso después de realizar una limpieza de datos y una corrección exhaustiva, es probable que permanezcan errores. Este reto puede ser en parte solventado durante el análisis de datos.
La escalabilidad de los datos: el constante y creciente volumen de datos es un desafío formidable para Big Data. Aunque en parte estas cuestiones han estado mitigadas por la gran y rápida evolución de los recursos de procesamiento y almacenamiento, hoy en día, los volúmenes de datos están creciendo más rápido que los recursos disponibles para su óptimo procesamiento y almacenamiento.
Velocidad y oportunidad: la velocidad de obtener información en un tiempo limitado que cumpla con los criterios especificados a priori en un sistema Big Data, es otro desafío que enfrenta el procesamiento de datos. Otros nuevos retos están relacionados con los tipos de criterios especificados y una necesidad de diseñar nuevas estructuras de indexación y de respuestas a las preguntas con plazos de respuesta muy ajustados.
Privacidad: los datos acerca de los individuos, tales como la información demográfica, las actividades de Internet, los patrones de comportamiento, las interacciones sociales o el uso de energía están siendo recogidos y analizados para diferentes propósitos.
Estas tecnologías y servicios de Big Data se enfrentan al reto de proteger la identidad y los atributos sensibles de datos en todo el ciclo de su procesamiento, debiendo respetar las diferentes políticas de protección de datos.
Perfiles profesionales en Big data
Big Data también representa un cambio sustancial por lo que respecta a los profesionales que deben llevarlo a cabo. Big Data requiere o demanda perfiles muy concretos y, por lo que parece ser, escasos, ya que, además de conocimientos técnicos específicos, deben tener la capacidad de observar lo que en el mundo anglosajón llaman big picture, es decir, ser capaces de observar las diferentes complejidades de los proyectos Big Data y su relación con las múltiples aristas que presentan los problemas en un entorno real de aplicación.

Estos nuevos perfiles profesionales, llamados generalmente “data scientists” o científicos de datos, recogen, filtran, procesan y transforman la información en consejos, recomendaciones o conocimiento, para que se puedan tomar decisiones tanto en el ámbito clínico, como en el de investigación o gestión sanitaria.
Este enfoque de la problemática hace que, aunque los profesionales suelen venir de estudios universitarios relacionados estrechamente con ingenierías o ciencias, en el día a día de su actividad, son quizás más gestores que programadores y, por tanto, deben poseer capacidades suficientes de gestión.
El papel del científico de datos es esencial desde el primer proceso relacionado con la selección de las herramientas. En primer lugar, porque deberá elegir entre las soluciones tecnológicas disponibles para resolver el problema planteado. Hasta ahora las soluciones de infraestructura en Big Data solían ser adhoc para cada una de las problemáticas a tratar. En segundo lugar, porque tendrá que dirigir o participar en la dirección, del proceso de resolución del problema.
Estos profesionales son demandados por su capacidad de trabajar con herramientas tecnológicas específicas y se les valora especialmente por sus conocimientos sobre estadística y programación y por sus habilidades para construir modelos de datos y realizar las preguntas adecuadas.
Fases de un proyecto Big Data
En la era previa al Big Data, las infraestructuras de datos estaban diseñadas y organizadas en torno a un conjunto de preguntas previamente conocidas y estructuradas a priori. Ahora mismo, en la era del Big Data, las preguntas iniciales que dan salida a la generación de información son menos predecibles.
Preguntas iniciales
Esta incertidumbre, respecto a las preguntas previas de la generación del conocimiento a partir de información, hace que las infraestructuras para el manejo de grandes volúmenes de datos se alejen de las aproximaciones tradicionales.
Como la capacidad del Big Data es enorme desde el punto de vista exploratorio, la formulación de las preguntas iniciales de investigación se configura como un elemento clave para la obtención de conocimiento, pero, a su vez, implica un cambio de perspectiva en su realización. Así, mientras queda claro que sin la pregunta adecuada, los datos y el posterior procesamiento de la información apenas tienen utilidad, cabe añadir que Big Data permite explorar y ver la realidad de los datos haciendo que un buen análisis sobre los mismos acabe generando nuevas preguntas que deberán buscar respuesta.
En este sentido, la fase inicial de un proyecto de Big Data parte de poder realizar las preguntas adecuadas. Lo importante es hacer las preguntas correctas y poseer los datos apropiados para responderlas. Sin estas condiciones el trabajo realizado sobre Big Data no generará el valor suficiente.
Creación del modelo
La fase siguiente a la definición de las preguntas iniciales de análisis se sustenta en la creación del modelo. Se definen las capacidades necesarias y sus funcionalidades para alinear la estructura de tecnología de la información disponible en la organización con las iniciativas que se deseen llevar a cabo con Big Data. Y, concretamente, será necesario:
1. Definir objetivos definitivos así como la estrategia para alcanzarlos. En esta primera fase de la creación del modelo, es imprescindible definir con precisión cuales son las metas que la organización desea alcanzar con el uso de Big Data, tanto desde la perspectiva holística que incluya al conjunto de la organización como aquellas más propias de algunos aspectos departamentales. Es también esencial que en la estrategia para alcanzarlos (roadmap) se tenga en cuenta que las necesidades deben ser alcanzables con los recursos disponibles en la organización.
2. En segundo lugar, la creación del modelo debe integrar un proceso completo para poder capturar, consolidar, gestionar y proteger la información necesaria. Esta información incluirá datos tanto estructurados como no estructurados y debe explicitar, de forma evidente, la disponibilidad de fuentes internas y externas de datos de que se dispone, así como la calidad y puntos débiles de las mismas. Evidentemente, es esencial conocer sobre todo qué datos no están disponibles para la organización.
3. Finalmente, deben identificarse los recursos humanos disponibles para llevar a cabo la implementación del modelo, teniendo en cuenta que son perfiles altamente especializados. Estas personas encargadas de llevar a buen puerto la obtención de datos, deben dominar la manipulación, procesamiento y almacenamiento de datos.
Elección tecnológica
En este caso, los responsables de su desarrollo, con especial relevancia por parte de los llamados científicos de datos, que serán los responsables de su explotación y análisis, deberán escoger entre el gran volumen de soluciones tecnológicas concretas existentes.
De forma habitual, las diferentes soluciones tecnológicas de software, sean de extracción, procesamiento o visualización de información, están basadas en código libre. La razón para ello tiene que ver con dos aspectos principales. El primer aspecto, la “juventud” de la tecnología implica que ningún proveedor de estos programas haya conseguido copar el mercado. Pero, el otro aspecto, la propia naturaleza adhoc de los proyectos Big Data facilita que, consecuentemente, también las herramientas se adapten a esta circunstancia. Las nuevas soluciones dan respuesta continuamente a nuevos problemas concretos que aparecen en relación a esta cuestión.
Finalmente, añadir que encontrar las soluciones de hardware necesarias, tanto por lo que respecta al almacenamiento y procesamiento de la información, como a las redes en las que el sistema completo debe sustentarse, es un punto crítico en esta fase del proyecto.
Implementación del modelo
Una vez realizada la elección tecnológica inicial se llevará a cabo la implementación del modelo. Esta implementación está, de forma general, estructurada en las siguientes fases:
Obtención y almacenamiento de los datos: la obtención de datos debe tener en cuenta las fuentes de los mismos en función de su origen. Por un lado, hay fuentes principales tanto online basadas en APIs que proporcionan clientes o servicios y que se van incorporando en "tiempo real" a los sistemas de almacenamiento. Por otro, fuentes offline (bases de datos relacionales o sistemas de ficheros muy grandes).
Preparación y transformación de los datos: esta fase de la implementación de la solución Big Data es una de las que más tiempo consume en toda la operación ya que es crítica para el éxito del sistema. En este sentido, son claves tanto la calidad de los mismos, como las cuestiones relativas a los diferentes problemas de interoperabilidad 4 del sistema.
Procesamiento: en esta fase se construyen los modelos analíticos para su explotación. Normalmente se utilizan casi todas las herramientas habituales de análisis de datos incluyendo, especialmente, aquellas técnicas procedente de la minería de datos como árboles de clasificación o redes neuronales.
Visualización: las herramientas de visualización deben poder resumir de forma inteligible la información de los repositorios para ayudar al investigador en la toma de decis iones.
Los avances en Machine Learning: Deep Learning
Machine Learning es un método de análisis de datos en donde el proceso de modelización analítico está automatizado. Esto se traduce en que los algoritmos que trabajan sobre los datos aprenden de forma iterativa a partir de los mismos y permite a los sistemas informáticos encontrar patrones ocultos en los datos. Este concepto iterativo es esencial, ya que por su propia naturaleza, Big Data incorpora continuamente nuevos datos al modelo que no hace sino aumentar de tamaño y por tanto los algoritmos continuamente están mejorando su aprendizaje.
A pesar de que los algoritmos de aprendizaje automático ya llevan muchos años siendo utilizados, es en los últimos tiempos cuando sus resultados han sido más espectaculares. Las razones son básicamente el abaratamiento por unidad de almacenamiento de la información; la cada vez mayor velocidad de proceso de la información; así como la consolidación de los nuevos modelos de computación distribuida que se han popularizado en los últimos años. Los sistemas automáticos cada vez son capaces de procesar y obtener información con mayor velocidad, eficiencia y con menor presencia humana en el proceso.
Básicamente, los algoritmos en Machine Learning se pueden segmentar en función de la intervención humana en 3 tipologías.
Aprendizaje supervisado: estos algoritmos se utilizan sobre todo cuando existen datos etiquetados históricos y se conoce el tipo de resultado que se quiere obtener. Mediante técnicas de clasificación o regresión se puede predecir el comportamiento futuro en función del histórico en el repositorio de datos. Estos algoritmos comparan los resultados obtenidos con los resultados esperables que conoce el sistema y, en función de las diferencias entre ambos, extrae la información que se desea.
Aprendizaje no supervisado: en el aprendizaje no supervisado, el modelo analítico no tiene de entrada resultados etiquetados, ni cuentan con resultados esperables, por lo cual por si mismos han de detectar patrones subyacentes en los datos sin necesidad de soporte alguno. Muchas de las aplicaciones de text mining siguen este modelo de aprendizaje.
Tipos híbridos de aprendizaje: los tipos híbridos, como los modelos semiestructurados o los modelos de aprendizaje por refuerzo, se sitúan en un estadio intermedio entre ambos. Se aplican cuando el proceso de etiquetaje no puede ser completo, por las razones que sea, por ejemplo porque representa un coste no asumible. En el caso de los sistemas por refuerzo también existe la particularidad que el sistema tiene marcado un objetivo deseable y, a partir de procesos de análisis iterativos por ensayo y error, va ajustando su modelización hasta obtener el mejor de los resultados posibles.
Uno de los tipos de algoritmos con mayor éxito en la actualidad son los conocidos como redes neuronales artificiales o ANN, (según sus siglas en inglés, Artificial Neural Networks). Este tipo de algoritmos simula el método de comprensión del cerebro humano. Existen desde los años 50 y 60 del siglo pasado, y durante este tiempo, han sufrido prometedores avances y claros retrocesos, siendo una de las barreras con las que se han encontrado tradicionalmente la dificultad de interpretar los datos resultantes.
Pero hoy en día, los avances en computación, han dado paso a lo que se está llamando el aprendizaje profundo, conocido internacionalmente por su expresión inglesa Deep Learning. Para muchos expertos, este nuevo campo está produciendo los mayores avances en inteligencia artificial desde el inicio de esta disciplina. Deep Learning utiliza modelos especiales de redes neuronales para la identificación de diversas unidades de información y su translación a aprendizaje y conocimiento. Deep Learning necesita una capacidad de proceso muy grande pero los actuales desarrollos en hardware por primera vez están permitiendo alcanzar resultados tangibles. Lo más significativo, en relación a esta cuestión, es que parece estar a punto de dar un salto enorme en relación a la capacidad de proceso.
Este salto es conocido como la computación cuántica. Un nuevo paradigma en el desarrollo y construcción de los ordenadores que serán utilizados en la próximas décadas y que, en teoría, alcanzarán capacidades de proceso extremadamente superiores a las actuales. Hoy en día ya se fabrican y venden algunos de estos superordenadores, de los cuales so lo disponen las grandes empresas tecnológicas o determinadas agencias gubernamentales. En principio, la combinación de algoritmos de tipo redes neuronales específicas de Deep Learning, conjuntamente con la capacidad de proceso de los ordenadores cuánticos, abren la puerta a posibilidades impensables hasta hace muy poco tiempo sobre la capacidad de las máquinas para procesar información y extraer conocimiento.
5G, Internet de las cosas, wearables y nuevos biosensores
El “Internet de las Cosas” es la creación de escenarios donde los objetos procesan e intercambian información. Este concepto, anterior incluso a Big Data, está tomando un nuevo impulso en los últimos tiempos y parece, según el consenso entre expertos sobre la cuestión, que en breve va a alcanzar una potencialidad mucho más relevante.
En general, y aplicando el concepto al mundo de la salud, se puede prever un futuro en donde este proceso de intercambio de información entre diferentes objetos puedan construir escenarios de cuidados inteligentes.
Una de las razones para explicar las elevadas expectativas que sobre este concepto se empiezan a depositar es el tremendo impulso que la velocidad de las conexiones está a punto de alcanzar. Diversas compañías tecnológicas, expertas en redes y repartidas a lo largo del planeta, están trabajando para acabar de desarrollar e implementar 5G, que se espera se establezca de forma más o menos general entre 2018 y 2020. Estas fechas están relacionadas con dos acontecimientos deportivos, los Juegos Olímpicos de Invierno en Corea del Sur en 2018 y los Juegos Olímpicos de Verano en Tokyo en 2020, que servirán de puesta de largo de esta nueva tecnología.
Esta tecnología promete aumentar de forma exponencial el ancho de banda disponible para las conexiones de Internet, pudiéndose aumentar por mil, pasando de los actuales 2Gb por segundo, de una conexión de banda ancha actual, aproximadamente hasta unos 2000 Gb por segundo.
En este sentido, se espera que alcanzar esta nueva velocidad de banda ancha permita finalmente el desarrollo real de Internet de las Cosas (IoT) y, según algunas previsiones, hasta 50.000 millones de objetos estarán interconectados -recibiendo y enviando información- para el año 2020.
Entre estos objetos están los llamados wearables que se configuran como uno de los elementos que pueden ser claves en la conformación de dichos escenarios de cuidados inteligentes. Un wearable aplicado en la salud es un dispositivo tecnológico que el paciente “lleva encima” y recoge y procesa información sobre su salud, tanto servicios de monitorización de constantes de cualquier índole hasta la presentación de los resultados procesados.
Actualmente ya existe una apuesta clara de los principales actores tecnológicos por fomentar el uso de wearables en salud, especialmente por lo que respecta a pulseras cuantificadoras y existe un mercado potencial de uso de wearables para el control y seguimiento de patologías crónicas y procesos de salud.
Estos wearables se complementan con una aplicación en el smartphone con el que se comunican y se puede ver el histórico de datos recogidos, consultar todo tipo de estadísticas y gestionar el objetivo propuesto mediante técnicas de gamificación, con la finalidad de conseguir mediante la introducción de determinadas estructuras lúdicas una mayor implicación del usuario.
Nuevas herramientas de visualización
En los últimos tiempos se están desarrollando avanzados sistemas de visualización de datos. Esta parte de los sistemas Big Data es, a la vez, donde la evolución de los sistemas ha sido más lenta hasta ahora, pero donde parece que las futuras aplicaciones pueden tener un mayor desarrollo.
Hasta ahora, los datos usados en estadísticas y presentaciones gráficas se pueden visualizar de muchos modos distintos, pero siempre manteniendo su naturaleza matemática y siguiendo unos patrones más o menos establecidos.
En este sentido, ya se empieza a hablar en algunos ámbitos de representaciones de la información más naturales y/o antropomórficas que simbolicen, de una forma más natural y propia al ser humano, los resultados de los procesos analíticos con datos masivos y poder comunicar información de datos de una forma similar a la que se cuenta una historia, por ejemplo.
En la actualidad, existen lenguajes de programación o bibliotecas capaces de crear visualizaciones a través de procesamientos o a través de JavaScript, que han cambiado dramáticamente.D3 por ejemplo, es muy popular en este momento y ha sustituido en gran parte todo el trabajo que antes se hacía con Flash. Cambios hacia una visualización de datos participativa también están ganando popularidad en estos momentos. La participación y el diálogo entre los datos y los usuarios de los mismos parece ser la próxima frontera en este ámbito.
Hadoop
Hadoop es un entorno de desarollo software para procesar, almacenar y analizar grandes volúmenes de datos
Características de Hadoop
Hadoop es distribuido, es decir que se ejecuta en un cluster. Un cluster es una red de computadoras interconectadas que trabajan coordinadamente.
Es escalable y aumenta su capacidad a medida que necesita mayor espacio o recursos para almacenar y procesar los datos. A mayor número de nodos, mayor capacidad.
Es tolerante a fallos. En hadoop el nodo maestro detecta si se producen fallos y reasigna las tareas a otros nodos que funcinen correctamente. El nodo maestro a su vez está duplicado por si hubiera fallos en él. Cuando el nodo errático se recupera se reintegra al trabajo.
Es software open source. Cualquiera con conocimientos suficientes puede modificar su código y redistribuirlo.
Estructura de Hadoop
Hadoop está compuesto por diversos programas y tecnologias. Al conjunto de estas tecnologías se le llama ecosistema Hadoop.
HDFS
Map Reduce
Enlaces de interés
A continuación tienes unos enlaces que te pueden resultar útiles si quieres saber más sobre Big Data:
La gestión del Big Data en la Inteligencia de Negocio.
Monta una estructura Big Data para tu empresa.
33 brilliant and free data sources. Revista Forbes.
Política de privacidad de Facebook.
Vídeo: Philip Evans: How data will transform business.
Vídeo: Tracking Malte Spitz
Documentación de interés
A continuación tienes una serie de documentos e informes que es conveniente que leas si quieres saber más sobre el Crowdfunding.